《mysql是怎样运行的》笔记
基础
Unix里mysql服务器程序:
mysqld:mysql服务器程序
mysqld_safe: 调用mysqld+监控进程+日志
mysql.server:启动脚本=调用mysqld_safe
mysql_multi:启动多个mysql服务器程序
启动客户端
mysql -h主机名 -u用户名 -p密码 -P端口
客户端和服务器连接的方法
TCP/IP
- 采用TCP协议,通过IP地址+端口号进行网络连接
- 通过skip-networking禁用
命名管道(windows)
- 启动服务器程序的命令中加上 –enable-named-pipe
- 启动客户端程序的命令中加入 –pipe 或者 –protocol=pipe 参数
共享内存(windows)
- 启动服务器程序的命令中加上 –shared-memory
- 在启动客户端程序的命令中加入 –protocol=memory
- 使用 共享内存 的方式进行通信的服务器进程和客户端进程必须在同一台 Windows 主机中
Unix域套接字文件(unix)
启动客户端程序的时候指定的主机名为 localhost ,或者指定了 –protocol=socket 的启动参数
MySQL 服务器程序默认监听的 Unix 域套接字文件路径为 /tmp/mysql.sock ,通过mysqld –socket=/tmp/a.txt修改套接字文件路径
客户端程序显式连接到unix域套接字路径 mysql -hlocalhost -uroot –socket=/tmp/a.txt -p
服务器处理客户端请求

连接管理
为了避免频繁创建和销毁进程,服务器不会立即删除刚退出的客户端连接线程,缓存起来,分配给下一个新连接进来的客户端。连接建立后,对应客户端的服务器进程会持续监控客户端发送的请求
解析与优化
查询缓存
缓冲sql请求,并在不同客户端之间共享
无法命中:任意字符不同,查询请求中包含某些系统函数、用户自定义变量和函数、一些系统表
失效:INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 、DROP DATABASE 语句
语法解析
是一个编译过程,涉及词法解析、语法分析、语义分析等阶段
提取查询信息到 MySQL 服务器内部使用的一些数据结构
查询优化
优化sql,生成执行计划,EXPLAIN 语句来查看某个语句的执行计划
MySQL 中磁盘和内存交互的基本单位是 页,页的大小一般是 16KB ,也就是 16384 字节,
存储引擎
对数据的存储和提取,MySQL server 完成了查询优化后,只需按照生成的执行计划调用底层存储引擎提供的API,获取到数据后
返回给客户端
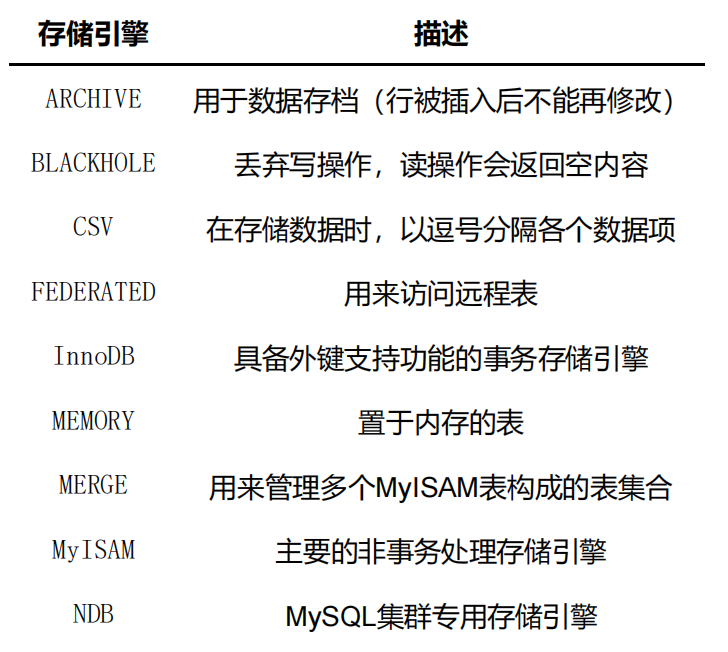
常用的就是 InnoDB 和 MyISAM
innodb 具有外键支持功能的事务春初引擎
myisam 主要的非事物处理引擎
配置文件
配置文件里就定义了许多个组,组名分别是 server 、 mysqld 、 mysqld_safe 、 client 、 mysql 、mysqladmin
配置文件优先级:如果我们在多个配置文件中设置了相同的启动选项,那以最后一个配置文件中的为准,将以最后一个出现的组中的启动选项为准,么以命令行中的启动选项为准
字符集(CHARACTER)和排序规则(COLLATION)
字符集(部分):
utf8mb3 :阉割过的 utf8 字符集,只使用1~3个字节表示字符。
utf8mb4 :正宗的 utf8 字符集,使用1~4个字节表示字符。
排序规则:
_ai :accent insensitive 不区分重音
_as : accent sensitive 区分重音
_ci : case insensitive 不区分大小写
_cs : case sensitive 区分大小写
_bin : binary 以二进制方式比较
MySQL 有4个级别的字符集和比较规则,分别是:
- 服务器级别
- 数据库级别
- 表级别
- 列级别
编码和解码使用的字符集不一致的后果
贝先 utf8编码 = 0xE8B49D 0xE58588(3个字节)
转gbk = 0xE8B4 0x9DE5 0x8588(1-2个字节 1个字节找不到 就2个字节)
显示 = 璐 濆 厛
GBK和文字在线转换:ASCII/GBK/GB2312中文汉字区位码,内码,编码在线查询软件 (23bei.com)
UTF-8和文字在线转换:UTF-8编码转换器-ME2在线工具 (metools.info)
MySQL中字符集的转换
服务器接收到客户端发送来的请求其实是一串二进制的字节,它会认为这串字节采用的字符集是character_set_client ,然后把这串字节转换为 character_set_connection 字符集编码的字符。最后使用 character_set_results字符集 返回客户端
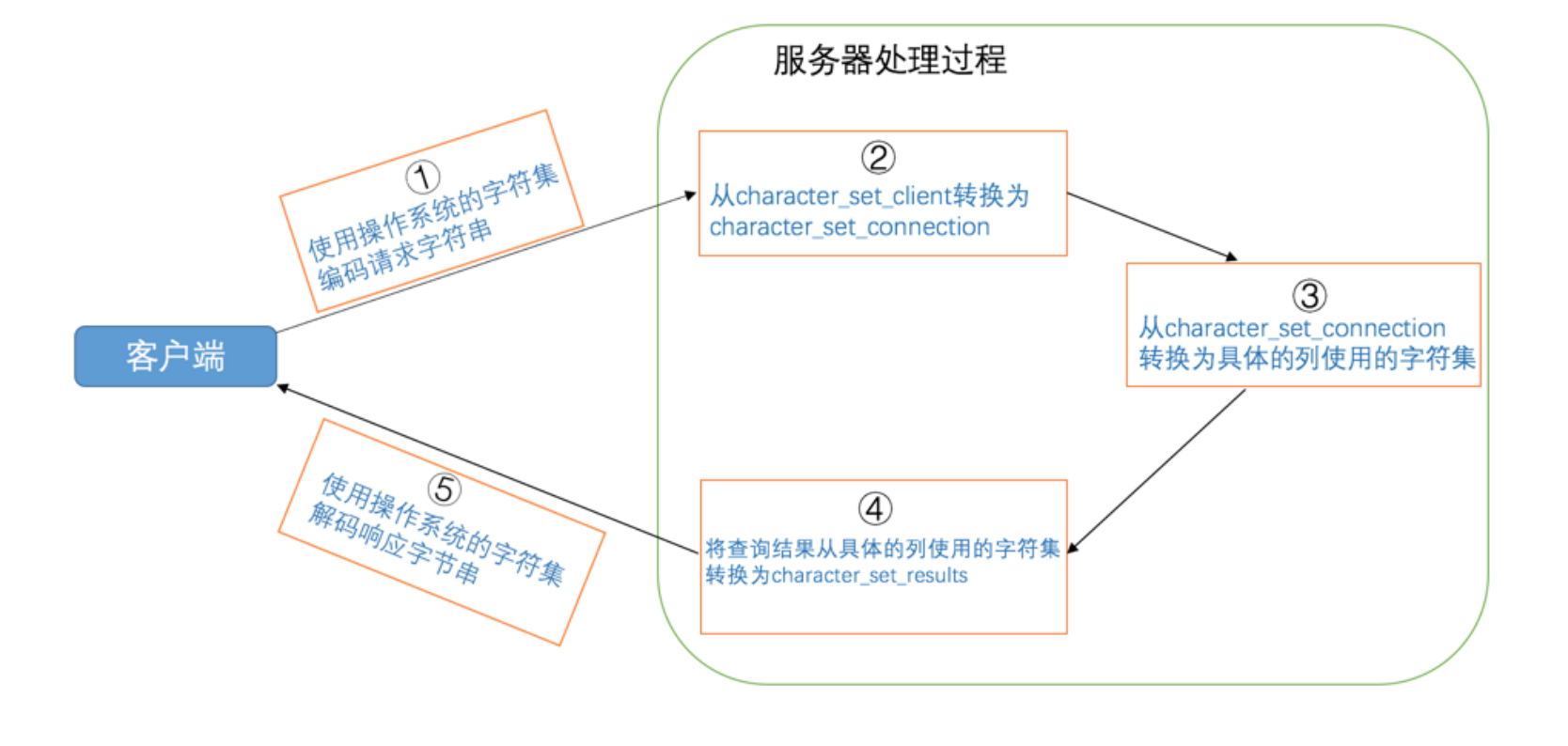
为避免乱码,确保一下三个字符集一致
character_set_client 服务器解码请求时使用的字符集
character_set_connection 服务器处理请求时会把请求字符串从 character_set_client 转为 character_set_connection
character_set_results 服务器向客户端返回数据时使用的字符集
在配置文件中添加default-character-set=utf8
[client]
default-character-set=utf8
Innodb
InnoDB 是一个将表中的数据存储到磁盘上的存储引擎,最大特色就是支持了ACID兼容的事务(Transaction)功能。
将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16 KB
是以记录为单位来向表中插入数据的,这些记录在磁盘上的存放方式也被称为 行格式 或者 记录格式
ACID:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)
行格式
- COMPACT行格式
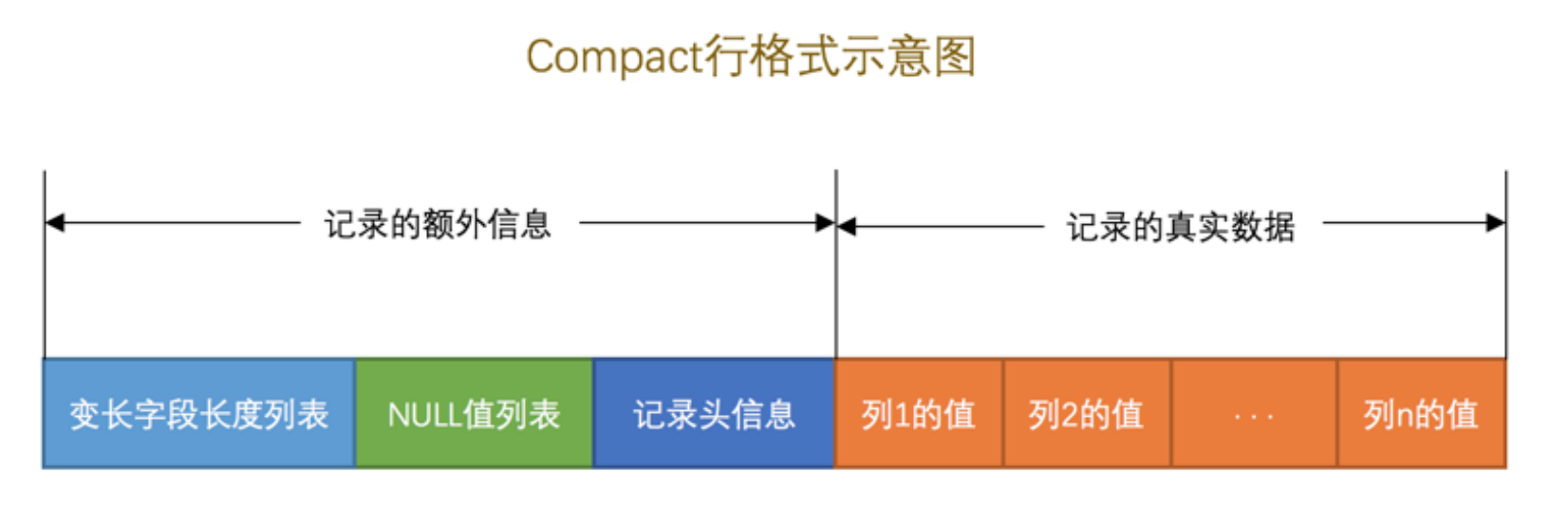
- Redundant行格式
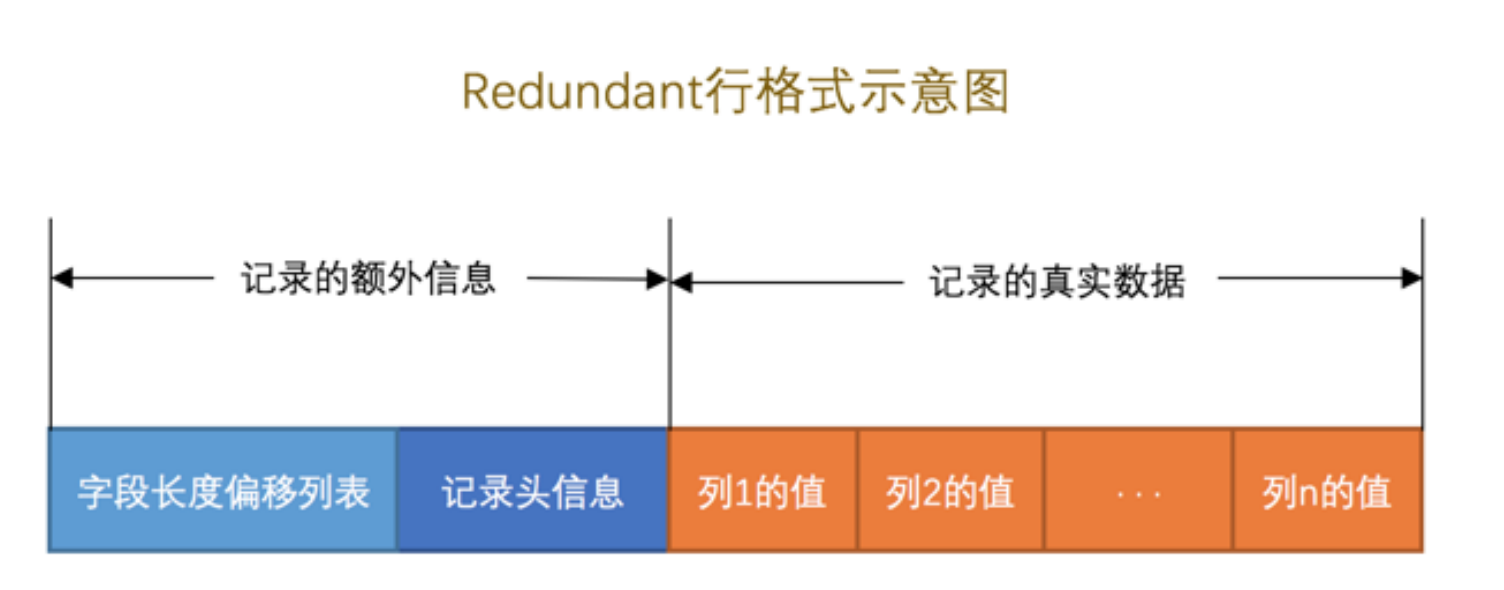
字段长度偏移列表 按照两个相邻数值的差值来计算各个列值的长度
Dynamic
行溢出处理:把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址
Compressed
Compressed 行格式会采用压缩算法对页面进行压缩,以节省空间。
varchar(M)最多能存储的数据
VARCHAR(M) 类型的列最多可以占用 65535 个字节 MySQL 对一条记录占用的最大存储空间是有限制的,除了 BLOB 或者 TEXT 类型的列之外,其他所有的列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过 65535 个字节
M = 真实数据+真实数据占用字节的长度+NULL 值标识(如果该列有 NOT NULL 属性则可以没有这部分存储空间)
如果该 VARCHAR 类型的列没有 NOT NULL 属性,那最多只能存储 65532 个字节的数据,因为真实数据的长度可能
占用2个字节, NULL 值标识需要占用1个字节:
真实数据占用字节的长度65535(十进制) = 11111111 11111111(二进制)= 2字节
65532 = 65535-2(真实数据占用字节的长度)-1(NULL 值标识)
65533 = 65535-2(真实数据占用字节的长度)-0(Not Null无需标识)
ascii 字符集(最多占用一个字节) 允许为null情况下可以最大65532 ,Not Null最大65533
gbk 字符集(最多占用2个字节) 允许为null情况下可以最大32766(65532 /2)
utf8 字符集(=utf8mb3 最多占用3个字节) 允许为null情况下可以最大21844(65532 /3)
行溢出
溢出原因:一个页一般是 16KB ,当记录中的数据太多,当前页放不下的时候,会把多余的数据存储到其他页中,这种现象称为 行溢出 。
解决方法:在 Compact 和 Reduntant 行格式中,在 记录的真实数据 处只会存储该列的一部分数据,把剩余的数据分散存储在几个其他的页中,然后 记录的真实数据 处用20个字节存储指向这些页的地址(当然这20个字节中还包括这些分散在其他页面中的数据的占用的字节数)
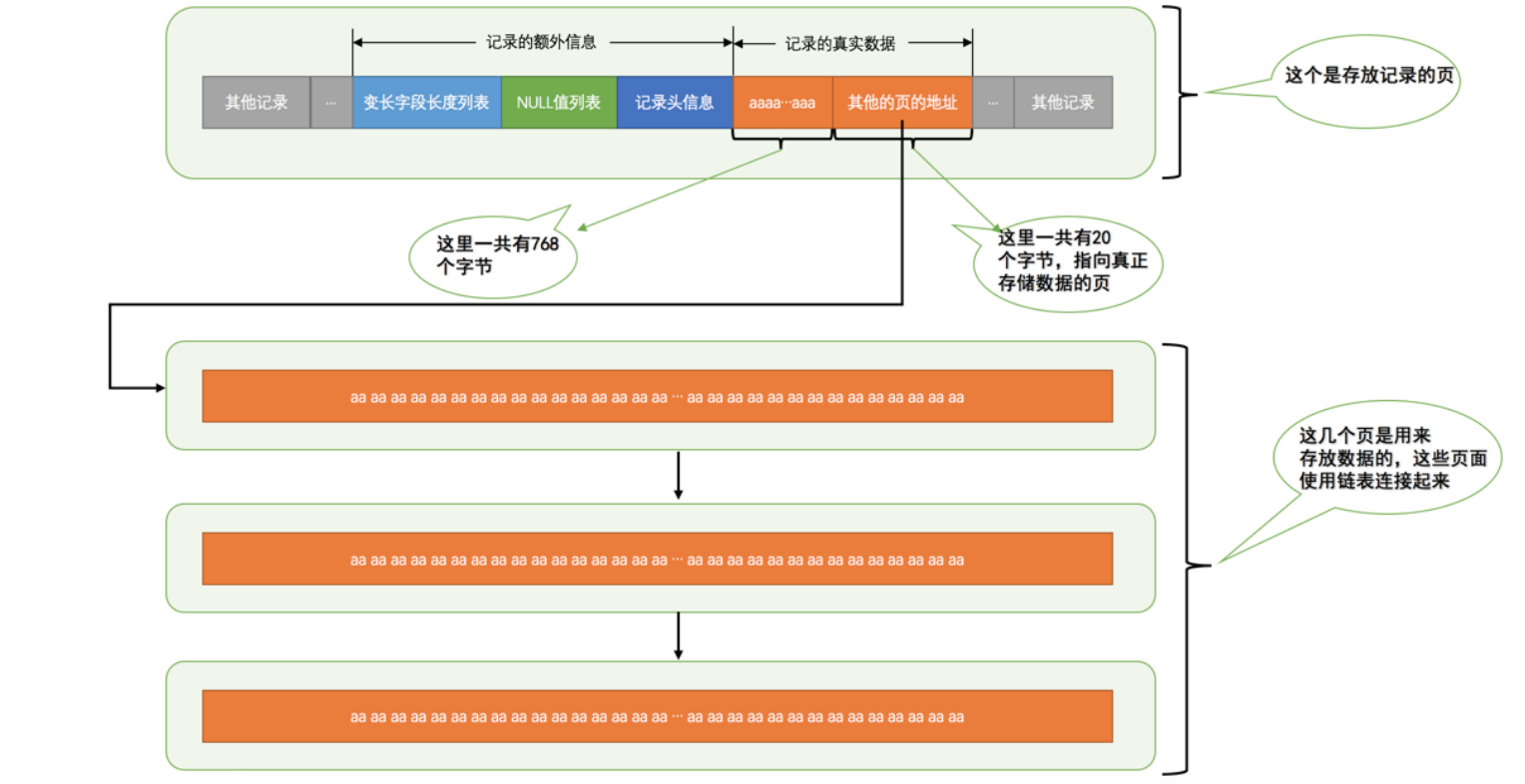
只要知道如果我们想一个行中存储了很大的数据时,可能发生 行溢出 的现象
索引页(数据页)结构
记录头信息
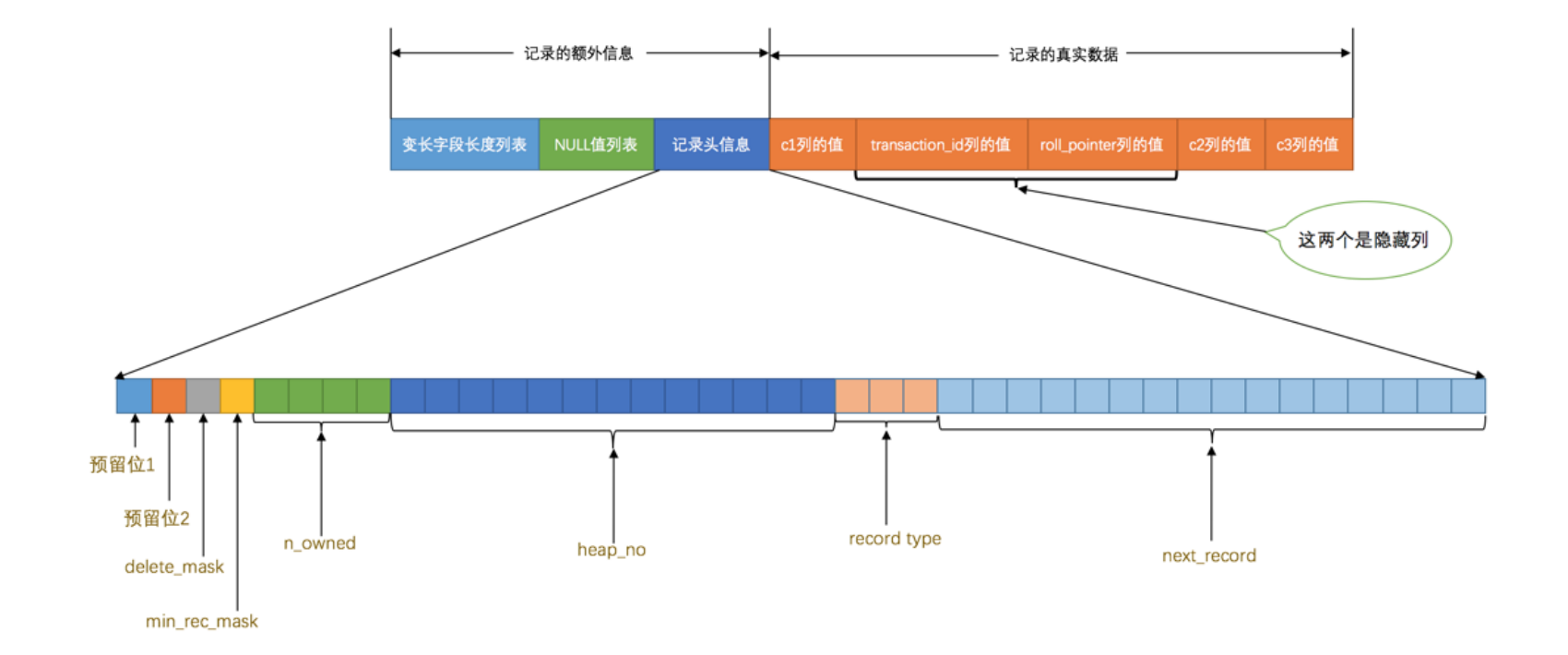
delete_mask:标记着当前记录是否被删除。立即删除重新排列影响性能,所有被删除掉的记录都会组成一个所谓的 垃圾链表 ,在这个链表中的记录占用的空间称之为所谓的 可重用空间 ,之后如果有新记录插入到表中的话,可能把这些被删除的记录占用的存储空间覆盖掉
min_rec_mask:
heap_no:当前记录在本 页 中的位置,innodb自动给页添加伪记录(虚拟记录),分别是最小记录和最大记录,以它们并不存放在 页 的 User Records 部分,他们被单独放在 Infimum + Supremum 。
record_type: 0 表示普通记录, 1 表示B+树非叶节点记录, 2 表示最小记录, 3 表示最大记录
next_record:从当前记录的真实数据到下一条记录的真实数据的地址偏移量。Infimum记录(也就是最小记录) 的下一条记录就是
本页中主键值最小的用户记录,而本页中主键值最大的用户记录的下一条记录就是 Supremum记录(也就是最大记录)
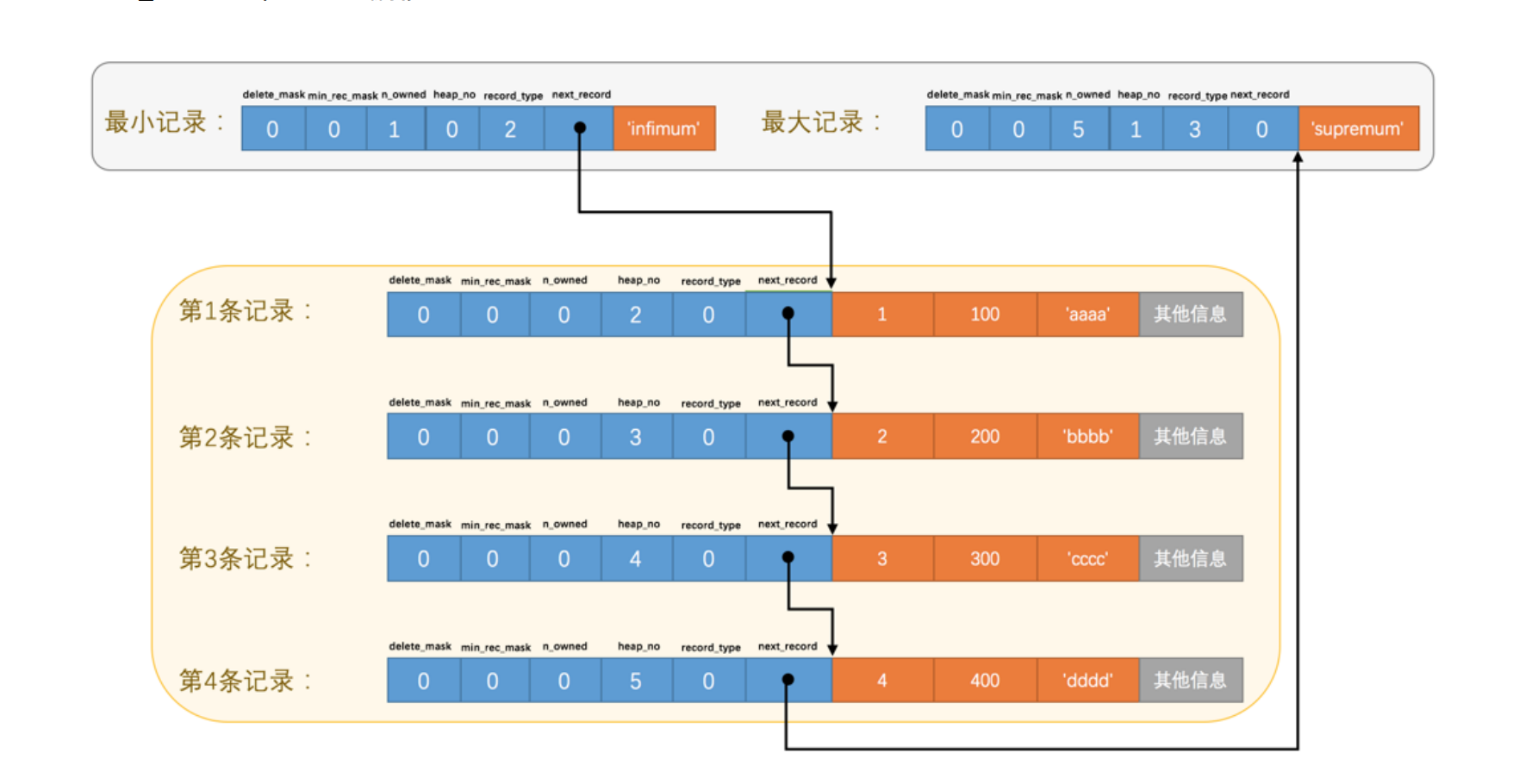
记录在页中按照主键值由小到大顺序串联成一个单链表
Page Directory页目录
- 将记录划分组
对每个分组中的记录条数是有规定的:对于最小记录所在的分组只能有 1 条记录,最大记录所在的分组拥有的记录条数只能在 1~8 条之间,剩下的分组中记录的条数范围只能在是 4~8 条之间
- 每组最后一条记录使用n_owned标记该组拥有几条记录
- 把每组的最后一条记录的地址偏移量按顺序存储到页的尾部(页目录),页目录中的地址偏移量称作slot槽
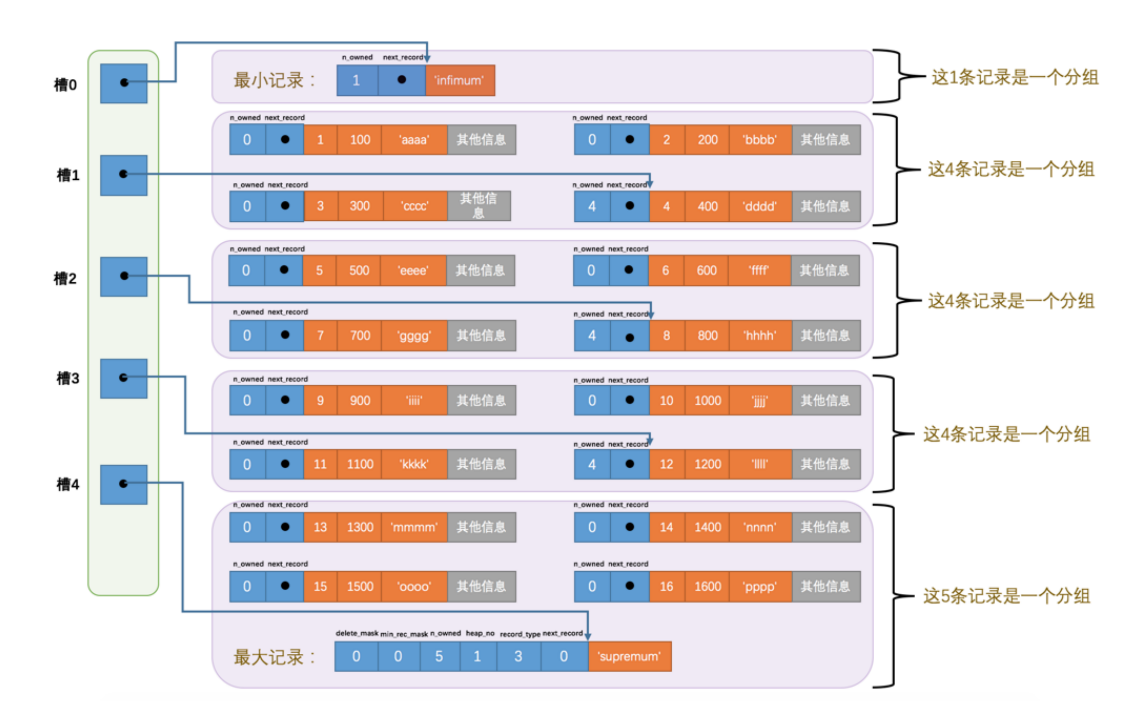
在一个数据页中查找主键记录的过程
通过二分法确定该记录所在的槽,并找到该槽中主键值最小的那条记录。
通过记录的 next_record 属性遍历该槽所在的组中的各个记录。
Page Header页头
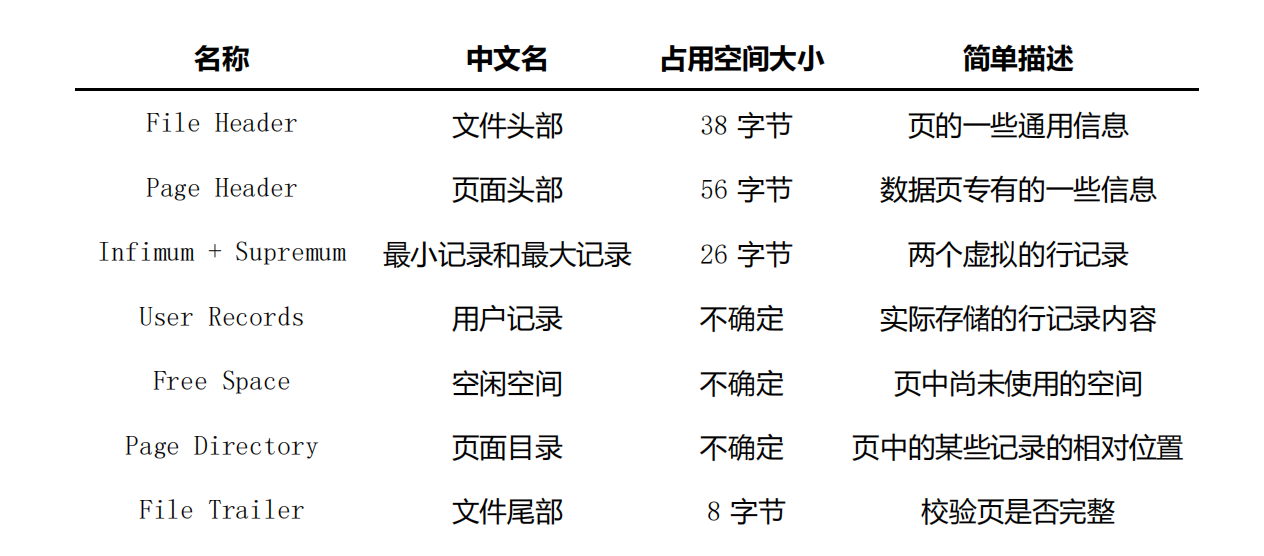
页 结构的第二部分,这个部分占用固定的 56 个字节,专门存储各种状态信息
File Header文件头部
固定占用的 38 个字节,针对 数据页 记录的各种状态信息
File Trailer
为保证从内存中同步到磁盘的页的完整性,在页的首部和尾部都会存储页中数据的校验和和页面最后修改时对应的 LSN 值,如果首部和尾部的校验和和 LSN 值校验不成功的话,就说明同步过程出现了问题
索引
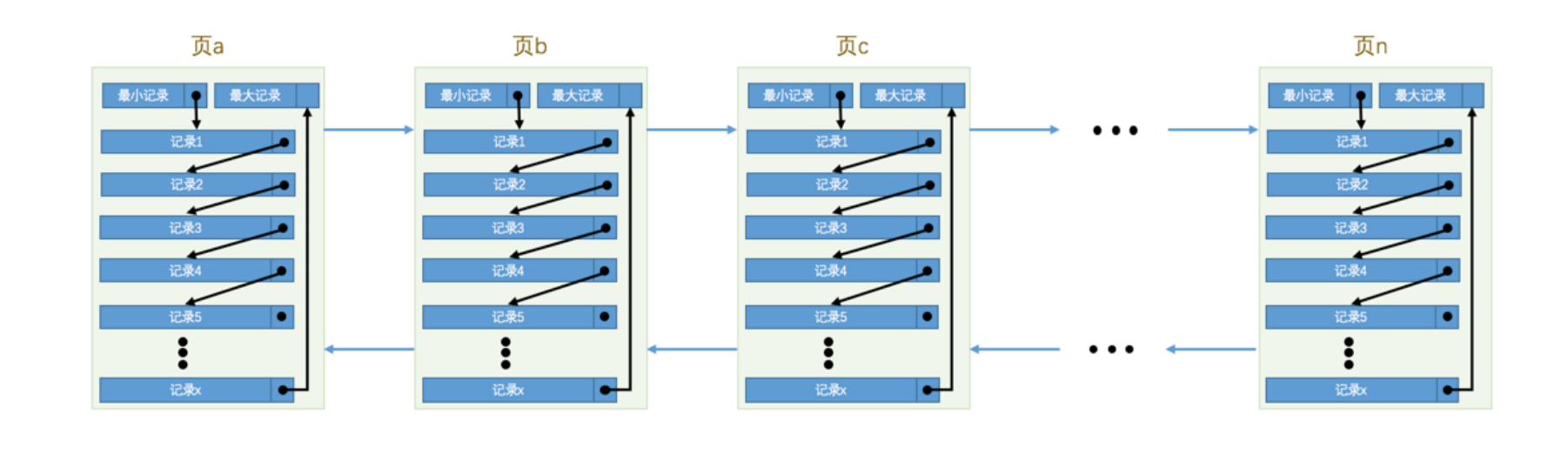
页分裂:在对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。
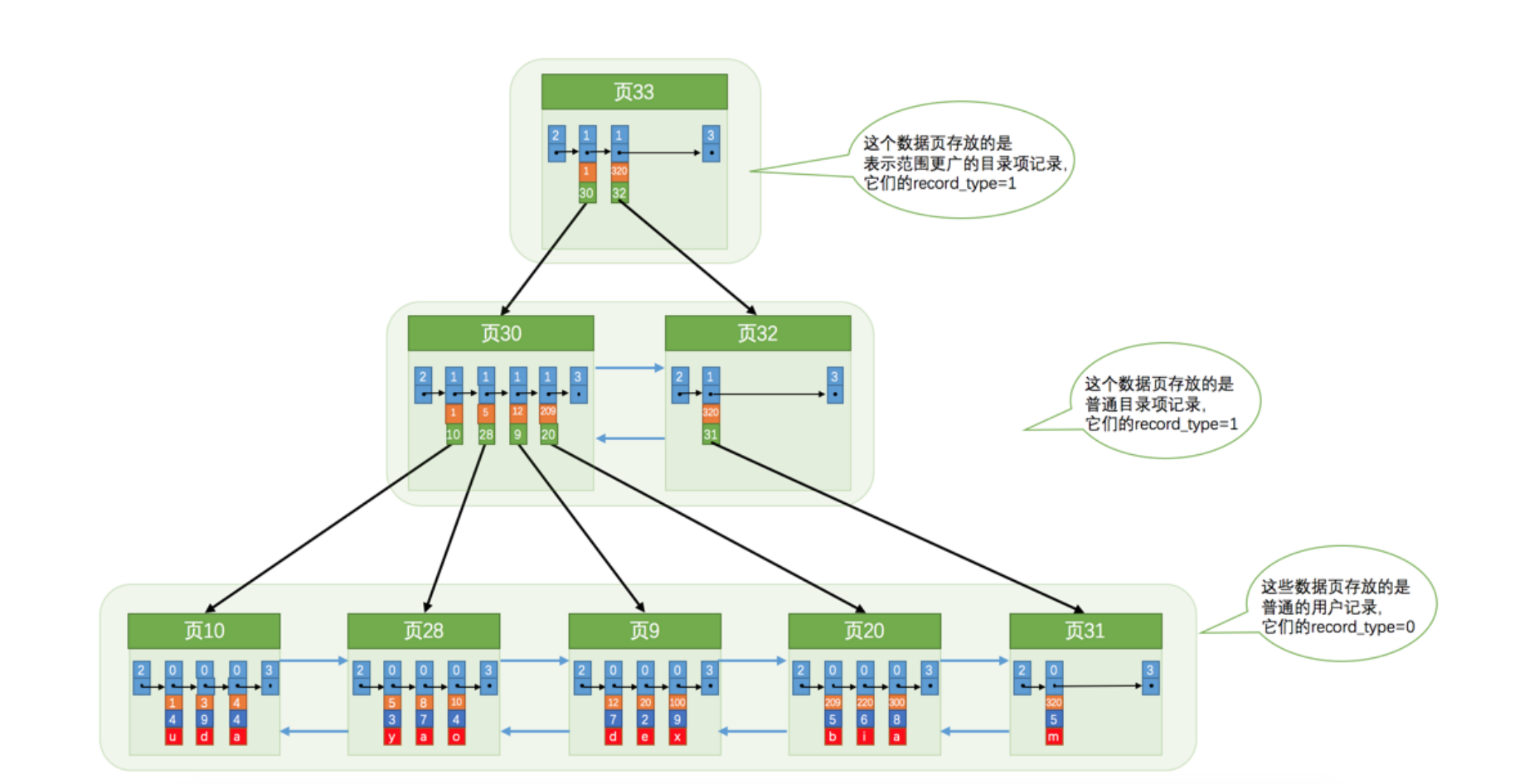
叶子结点是用户记录,非叶子结点是目录项纪录
聚簇索引:InnoDB 存储引擎会自动的为我们创建聚簇索引。
- 使用记录主键值的大小进行记录和页的排序
- B+ 树的叶子节点存储的是完整的用户记录
二级索引:在二级索引根据索引列查到对应主键,根据主键在聚簇索引找完整数据(回表)
- 使用记录索引列的大小进行记录和页的排序
- B+ 树的叶子节点存储的并不是完整的用户记录,而只是索引列+主键 这两个列的值。
- 目录项记录中不再是 主键+页号 的搭配,而变成了 索引列+页号 的搭配
联合索引:同时以多个列的大小作为排序规则,也就是同时为多个列建立索引
记录插入B+树过程:
- 根结点(表自动生成)
- 记录插入根节点
- 再插入数据 根节点空间不足 复制根节点
- 页分裂(两个子节点)
- 根节点 便升级为存储目录项记录的页。
结论:
每个索引都对应一棵 B+ 树, B+ 树分为好多层,最下边一层是叶子节点,其余的是内节点。所有用户记录都存储在 B+ 树的叶子节点,所有 目录项记录 都存储在内节点。
InnoDB 存储引擎会自动为主键(如果没有它会自动帮我们添加)建立 聚簇索引 ,聚簇索引的叶子节点包含完整的用户记录。
我们可以为自己感兴趣的列建立 二级索引 , 二级索引 的叶子节点包含的用户记录由 索引列 + 主键 组成,所以如果想通过 二级索引 来查找完整的用户记录的话,需要通过 回表 操作,也就是在通过 二级索引找到主键值之后再到 聚簇索引 中查找完整的用户记录。B+ 树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是 联合索引 的话,则页面和记录先按照 联合索引 前边的列排序,如果该列值相同,再按照 联合索引 后边的列排序。通过索引查找记录是从 B+ 树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了Page Directory (页目录),所以在这些页面中的查找非常快。
索引的代价
- 空间上的代价
- 时间上的代价
每次对表中的数据进行增、删、改操作时,都需要去修改各个 B+ 树索引。
搜索语句中也可以不用包含全部联合索引中的列,只包含左边的就行
前缀都是排好序的,所以对于字符串类型的索引列来说,我们只匹配它的前缀也是可以快速定位记录
联合索引,如果对多个列同时进行范围查找的话,只有对索引最左边的那个列进行范围查找的时候才能用到 B+ 树索引
于同一个联合索引来说,虽然对多个列都进行范围查找时只能用到最左边那个索引列,但是如果左边的列是精确查找,则右边的列可以进行范围查找
不可以使用索引进行排序的几种情况
- DESC混用
- WHERE子句中出现非排序使用到的索引列
- 排序列包含非同一个索引的列
- 排序列使用了复杂的表达式
回表
需要回表的记录越多,使用二级索引的性能就越低,
为了彻底告别 回表 操作带来的性能损耗,我们建议:最好在查询列表里只包含索引列,
索引字符串值的前缀 : 只对字符串的前几个字符进行索引
KEY idx_name_birthday_phone_number (name(10), birthday, phone_number)
如果索引列在比较表达式中不是以单独列的形式出现,而是以某个表达式,或者函数调用形式出现的话,是用不到索引的
主键插入顺序
中间插入主键会导致页分裂,导致性能损耗,最好让插入的记录的主键值依次递增,这样就不会发生这样的性能损耗了。所以我们建议:让主键具有 AUTO_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入
结论:
B+ 树索引在空间和时间上都有代价,所以没事儿别瞎建索引。
B+ 树索引适用于下边这些情况:
全值匹配
匹配左边的列
匹配范围值
精确匹配某一列并范围匹配另外一列
用于排序
用于分组
- 在使用索引时需要注意下边这些事项:
只为用于搜索、排序或分组的列创建索引
为列的基数大的列创建索引
索引列的类型尽量小
可以只对字符串值的前缀建立索引
只有索引列在比较表达式中单独出现才可以适用索引
为了尽可能少的让 聚簇索引 发生页面分裂和记录移位的情况,建议让主键拥有 AUTO_INCREMENT 属性。
定位并删除表中的重复和冗余索引
尽量使用 覆盖索引 进行查询,避免 回表 带来的性能损耗。
InnoDB的表空间
区 ( extent ):64页
段(segment):存放叶子节点的区的集合就算是一个 段 ( segment ),存放非叶子节点的区的集合也算是一个 段 。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。链表中相邻的两个页,物理位置可能离得非常远,会产生 随机I/O,在磁盘中访问速度慢,尽量把页放在相邻的位置
在刚开始向表中插入数据的时候,段是从某个碎片区以单个页面为单位来分配存储空间的。
当某个段已经占用了32个碎片区页面之后,就会以完整的区为单位来分配存储空间。